机构名称:
¥ 1.0
摘要。视频时间基础旨在确定与给定自然语言查询最相关的未修剪视频中的视频片段。现有的视频时间本地化模型依靠特定的数据集进行培训,数据收集成本很高,但在跨数据库和分发(OOD)设置下表现出较差的概括能力。在本文中,我们提出了一种降雨,以利用预先训练的大型模型的能力,从而利用了EDEO T EMPORAL G圆形(TFVTG)方法。天真的基准是在视频中列举建议,并使用预先训练的视觉语言模型(VLM)根据视觉语言对齐来选择最佳建议。然而,大多数Exting VLM都经过图像文本对或修剪的视频剪辑对训练,这使得(1)抓住关系并区分同一视频中多个事件的时间边界; (2)在视频中理解并敏感事件的动态过渡(从一个事件到另一个事件的过渡)。要解决这些问题,首先,我们建议利用大型语言模型(LLMS)分析查询文本中包含的多个子事件,并分析这些事件之间的时间顺序和关系。其次,我们将一个子事件分为动态过渡和静态状态部分,并使用VLMS提出动态和静态评分功能,以更好地评估事件和描述之间的相关性。代码可在https://github.com/minghangz/tfvtg上找到。最后,对于LLMS提供的每个子事件描述,我们使用VLMS定位与描述最相关的TOP-K提案,并利用LLMS提供的子事件的OR-DER和关系来过滤和集成这些建议。我们的方法在Charades-STA和ActivityNet字幕数据集上的零照片视频基础上实现了最佳性能,而无需进行任何培训,并在跨数据库和OOD设置中展示了更好的通用功能。
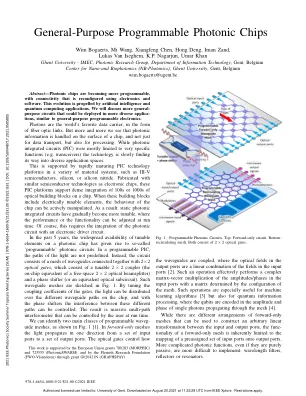
可见干涉测量法的光子芯片
主要关键词





相关文件推荐